I have no data to back this up (a great way to start a blog about data), but I think when people visit a museum’s online collection there are two kinds of things they’re likely to type in a search box if you give them the chance 1) something specific and relevant to that collection 2) an animal they like. For somewhere like the Whitney the former is largely solvable with existing metadata, but the latter presents a real problem. How do you tag a constantly growing collection of tens of thousands of objects with terms that may also shift and change over time? The answer might ideally be “carefully” and “with actual people”, but this is Museums and everyone is already busy.
For a few years we’ve been using Google’s Vision API to automatically keyword tag artworks in our collection, after a brief flirtation with AWS’ Rekognition. This has always been an internal staff-only feature, as it’s never felt particularly accurate and has a huge amount of noise with bad tags. But in limited use it can be really helpful—if there’s a big storm in NYC and we want to post something like an image of lightning, the Google Vision API has been fairly good at that kind of labeling, making up for the fact that not every artwork with lightning in it would neccessarily have it in the title. It’s also been alright if you want like, cats (though it’s oddly less good at birds or whales). But considering we’re a museum with a huge amount of contemporary art, with people and their bodies and complex social contexts…it’s just been too much to feel comfortable making these tags public without some kind of serious review, and the tags spit out by Google Vision are often quite basic and unhelpful anyways.
ENTER GPT4
Of course the story with AI over the last year has been dominated by OpenAI and GPT4, and with the public launch of GPT4 with Vision the opportunity for testing it at image tagging became available. This is something I’ve been quite excited about, because as best as I can tell Google Vision has stayed pretty unchanging in the years we’ve used it, and my hope has been that GPT4 with Vision might offer a generational leap forward.
The methodology
To compare GPT4 with Vision and Google Vision, I coded the output from running both over 50 random works in the Whitney’s collection that have public images. For Google Vision I used the Google Vision API’s label detection functionality, and for GPT4 I gave it the following prompt:
Create a comma separated list of keywords for the image
From there I coded the resulting keywords into 3 categories: “good”, “okay”, and “bad”. “Good” means the keyword is accurate and useful, “okay” means it’s technically true but not very useful, and “bad” means it’s straight up wrong.
There’s a lot of caveats and considerations here including:
- What’s good/okay/bad is still quite subjective.
- Because it’s a random 50 works, it doesn’t cover all the kinds of artworks in the collection (i.e. we have way more prints and drawings than we do installations or films).
- The GPT4 completions were not limited to a specific number of keywords, while Google almost always gave back exactly 10 (the default).
- GPT4 is less deterministic than the Google model, so output can vary more widely each time it’s run.
- I’m ignoring Google’s confidence scoring on labels.
- I’m sure someone else can write a better GPT4 prompt.
But something is better than nothing.
The results
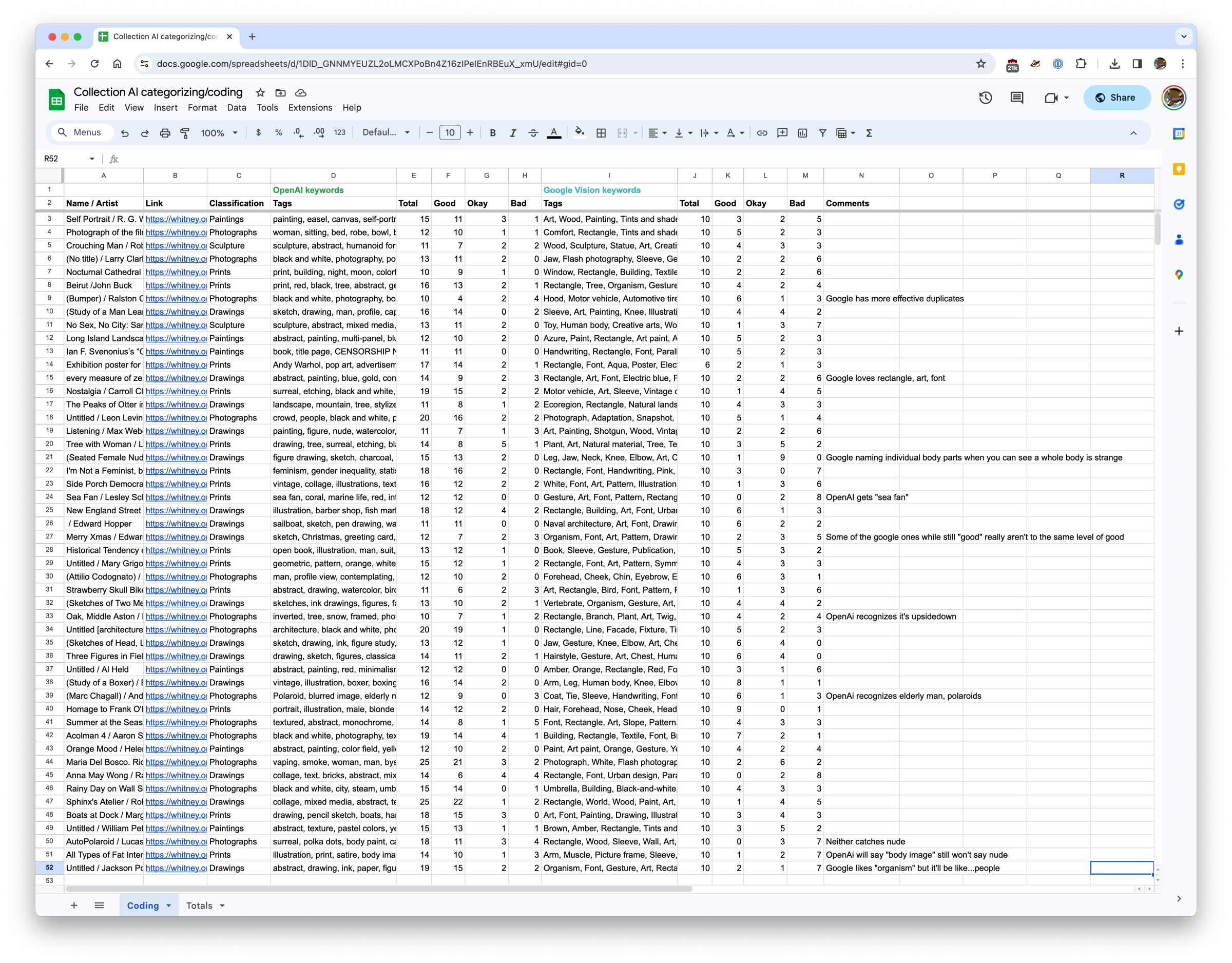
After a few hours coding all of the keywords for 50 artwork images (on top of more anecdotal investigation), it’s clear that GPT4 is returning much better results than Google Vision. On a basic level the results are:
OpenAI GPT4 with Vision keywords
Good: 576
Okay: 86
Bad: 69
Total: 730
Google Vision label detection keywords
Good: 177
Okay: 131
Bad: 189
Total: 496
Overall GPT4 returned keywords that were 79% “good” compared to Google Vision’s 36%. And Google dwarfed GPT4 in terms of bad keywords, with fully 38% being “bad” compared to only 9.5% of GPT4’s. But this doesn’t even tell the full story.
Quality AND quantity
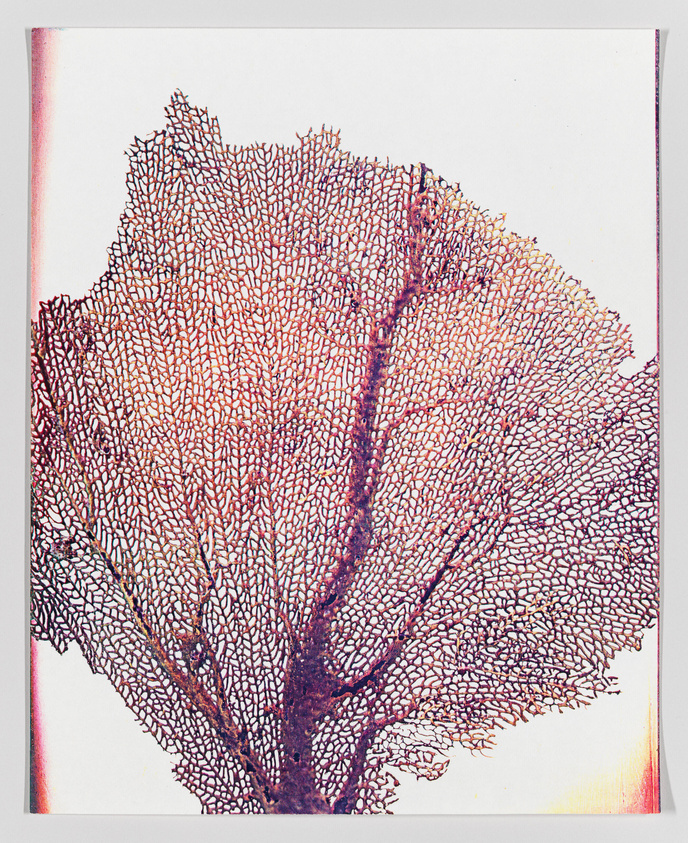
The quality of GPT4’s keywords more often than not put Google Vision’s to shame. For the above work, Lesley Schiff’s Sea Fan, here are the two sets of tags:
GPT4
sea fan, coral, marine life, red, intricate, natural pattern, underwater organism, fan-shaped, marine biology, texture, ocean, delicate structure
Google Vision
Gesture, Art, Font, Pattern, Rectangle, Visual arts, Drawing, Illustration, Printmaking, Painting
…or how about for the below work, Edward Hopper’s Merry Xmas:

GPT4
sketch, Christmas, greeting card, Merry Xmas, cats, piano keys, musical theme, black and white, ink drawing, whimsical, holiday message, to Pop, from Marion
Google Vision
Organism, Font, Art, Pattern, Drawing, Illustration, Visual arts, Rectangle, Line art, Artwork
GPT4 is able to be specific in its keywords in a way that Google is not. Tags like “sea fan” and “delicate structure” are up against “art” and “pattern” in the case of Sea Fan. In Merry Xmas, it’s tags like “Christmas” and “ink drawing” versus “Organism” and “drawing”. Individually none of these provide a slam dunk winner (especially given the errors GPT4 made with Merry Xmas) but over a sequence of 50 images this trend of greater specificity broadly holds true.
A large number of both the “good” and “okay” Google Vision keywords are things like “art” or “rectangle”, and anytime there’s a person it often just names different parts of their body that while technically visible are not the focus. GPT4 by contrast tends to only use those keywords when they’re particularly prominent. GPT4 will label a Guerilla Girls poster with “feminism” and “gender inequality” while Google Vision will only say “poster” and “handwriting”. GPT4 also shows a greater understanding of context. Consider this work by Rodney Graham:

GPT4
inverted, tree, snow, framed, photograph, winter, landscape, surreal, nature, upside-down
Google Vision
Rectangle, Branch, Plant, Art, Twig, Tints and shades, Tree, Font, Painting, Visual arts
Visually by far the most defining aspects of this photograph are that it is a) of a tree and b) upside down. Google gets the “tree” just like GPT4, but it does not give anything indicating the inversion. Google also adds maybe technically true tags like “twig” and “tints and shades”, but how useful are those?
GPT4 not only does better on the details, but when it misses you can often tend to see how it got confused. It’s far more understandable to interpret what appears to be regular grass as potentially snow-covered than it is to categorize this whole image as a painting like Google.
Conclusions
Without claiming that this is in any way an exhaustive comparison, it is still abundantly clear that for many of the kinds of works in the Whitney’s collection GPT4 with Vision is much better at keyword tagging than Google Vision. Annecdotally and through this (limited) analysis, the two are far enough apart that there really isn’t any question on what’s more useful for us. If anything, this raises the much thornier question on if this is good enough to incorporate into the public interface of the collection.
Full disclosure, it’s at this point I was planning to use Henry Taylor’s THE TIMES THAY AINT A CHANGING, FAST ENOUGH! as an example of where GPT4 could make the kind of mistake that would throw some ice water on that consideration.

When I first started experimenting with GPT4 with Vision, GPT4 would tend to describe this image as being abstract, inside a car, with a bear in the backseat. What the painting actually shows is the murder of Philando Castile in his car by a police officer in 2016. While it isn’t necessarily surprising that an algorithm might mistake Taylor’s stylized abstraction of a man for something else, given the documented history of racism by AI/ML algorithms, this isn’t the kind of mistake to be shrugged off. But when I re-ran this image through our tagging pipeline the current keywords were:
GPT4
abstract, painting, colorful, modern art, bold lines, geometric shapes, blue background, yellow, green, white, black, brush strokes, contemporary
Google Vision
World, Organism, Paint, Art, Creative arts, Font, Rectangle, Painting, Tints and shades, Pattern
No bear.
I’m not entirely sure what to make of this. The lack of determinism with GPT4 may mean that run enough times, I’d get back the problematic keywords once again (though at the time of writing this and running it half a dozen times I’m not). Or it’s possible the model has changed enough since I first started working with it that this wouldn’t happen anymore. I have no way to know.
The actual conclusion
GPT4 with Vision is a big enough improvement over Google Vision label detection that it was an easy decision to swap over our internal usage to it. Whether this is good enough to utilize publicly, and can be contextualized well enough or the prompt massaged enough to blunt the concerns of bad keywords, I’m still unsure. An imperfect tool is a lot easier to explain to staff who use our online collection regularly than it is to a person who might come to our site once from a link someone else shared with them, and a lot less likely to cause harm.
There’s clearly a lot of promise here, and I hope we can find ways to utilize it.